0. 들어가기 전
RAG의 정석 - 개념편
- RAG(Retrieval-Augmented Generation) | RAG 간단하게 알아보기
- LLM을 Chain하고 턴을 종료한다. | LangChain 개념 및 사용법
RAG의 정석 - 취약점편
- CVE-2023-7018 | huggingface/transformers - Deserialization of Untrusted Data
- CVE-2024-23751 | LlamaIndex/LlamaIndex - SQL Injection << NOW!
1. Introduction
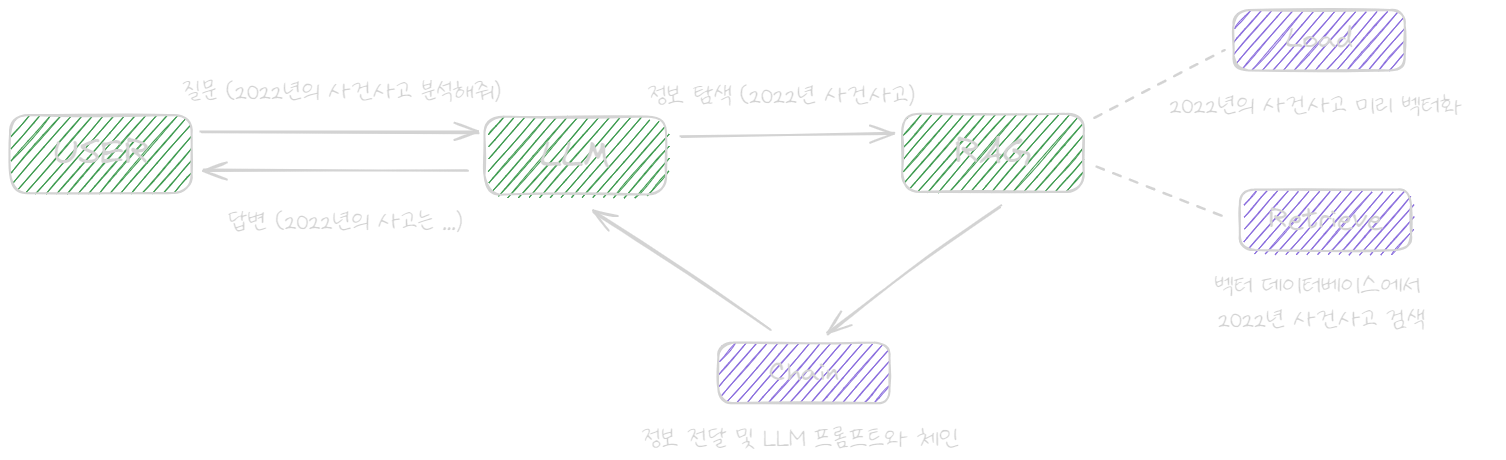
RAG는 LLM의 정확성을 높이기 위해 외부 데이터에서 정보를 검색하여 활용하는 기술입니다.
모델을 다시 교육할 필요 없이 지식을 확장할 수 있기에 효율적인 비용으로 관련성, 정확성 및 유용성을 유지할 수 있습니다.
크게 ’검색 및 사전 처리’와 ‘생성’ 두 가지 단계로 이루어져 있습니다.
RAG는 효율적인 검색/조회를 위해 벡터 데이터베이스를 활용합니다.
1.1. 검색 및 사전 처리
강력한 검색 알고리즘을 활용하여 웹, 기술 자료, 데이터베이스와 같은 *외부 데이터를 질의합니다.
검색된 정보는 토큰화(tokenize), 어간 추출, 금지어 제거 등의 사전 처리 과정을 거칩니다.
* 외부 데이터: LLM의 원래 학습 데이터 세트 외부에 있는 새 데이터로 파일, 텍스트 등 다양한 형식으로 존재
1.2. 생성
사전 처리된 검색 정보를 선행 학습된 LLM에 통합합니다.
이런 통합을 통해 LLM이 정확하고 유익하며 몰입도 높은 대답을 생성할 수 있게 합니다.
(주제를 보다 포괄적으로 이해하도록 유도할 수 있습니다.)
2. Why RAG
기존 LLM의 많은 문제점 중, 아래 문제점들을 해결하기 위해 만들어진 것이 RAG입니다.
- 마땅한 답변이 없을 때 허위 정보를 제공(Hallucination)
- 오래되었거나 일반적인 정보 제공
- 신뢰할 수 없는 출처로부터 응답 생성
- 용어 혼동으로 인한 부정확한 응답
2.1. 비용 효율적인 구현
LLM 모델을 재교육하지 않고 새 데이터를 도입할 수 있으며, 교육 비용을 아낄 수 있습니다.
- 생성형 인공지능 기술을 폭넓게 접근하고 사용
2.2. 최신 정보
RAG를 이용해 LLM 모델에 최신 연구, 통계 또는 뉴스를 제공할 수 있습니다.
- Live social media feed (e.g. instagram, facebook)
- Other information source (e.g. Journal, Wikipedia)
- News
2.3. 사용자 신뢰 강화
RAG는 저작자 표시를 통해 정확한 정보를 제공하고, 사용자가 검증할 수 있도록 합니다.
- 출력에 소스에 대한 인용 or 참조를 포함
2.4. Factual Grounding
엄선된 정보에 접근할 수 있게 하고, 사실기반 정보에 grounding되어 있는지 확인합니다.
- 정확성이 가장 중요한 애플리케이션(e.g. News, Science Journal)에 유용
- Hallucination(환각현상)이 전송되는 것을 방지하는 데 도움
2.5. Context 관련성
RAG의 검색 매커니즘은 query 혹은 context와 관련 있는 정보가 검색되도록 보장합니다.
- 관련이 없거나 주제에서 벗어난 대답이 생성되지 않도록 도움
- LLM 모델이 특정 Context에 더 일관성 있고 적절한 대답을 생성하도록 지원
2.6. Vector Database
Vector Database를 활용하여 관련 문서를 효율적으로 검색합니다.
- 문서를 고차원 공간에 벡터 형식으로 저장하므로 유사성을 기반으로 빠르고 정확하게 검색
2.7. 개발자 제어 강화
RAG를 사용해서 LLM을 효율적으로 테스트하고 개선합니다.
- 정보 소스를 제어하고 변경하여 변화하는 요구 사항 혹은 부서 간 사용에 적응
- 민감한 정보 검색을 다양한 인증 수준으로 제한하고 LLM이 적절한 응답을 생성하도록 조정
- 잘못된 정보 소스를 참조하는 경우에 문제를 해결하고 수정하는 데 용이
3. 동작 방식
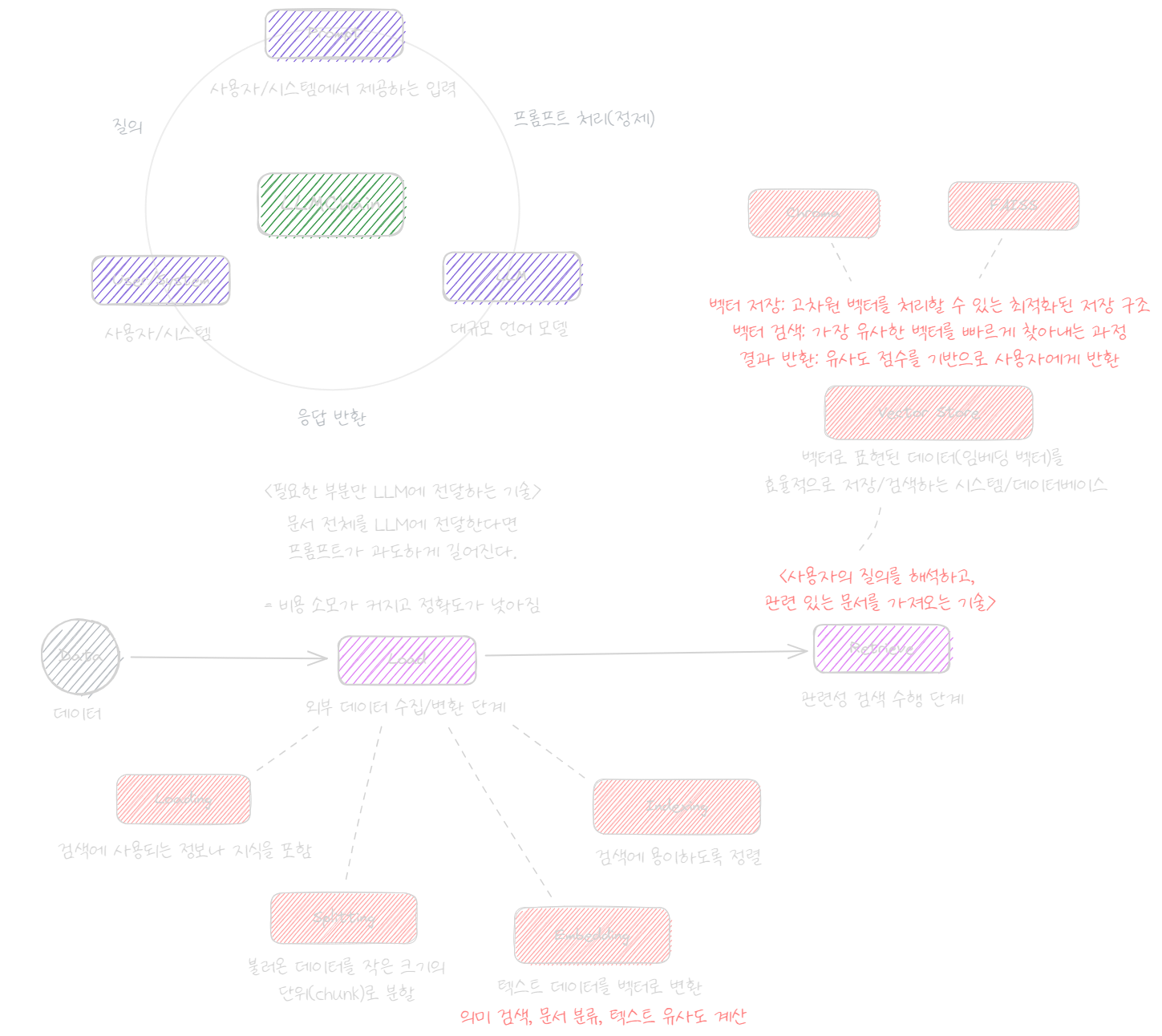
- 외부 데이터를 수집 (Load)
- 검색하기 쉬운 형태로 가공 (Tokenize, Chunking)
- 가공된 데이터를 변환 (Embedding)
- 가공된 외부 데이터를 벡터 데이터베이스에 저장 (Store)
- 사용자의 질의(LLM)을 바탕으로 벡터 데이터베이스에서 관련 정보 검색 (Retrieve)
- 검색된 지식을 활용해 사용자 질문에 대한 답변 생성 (Generate)
LLM은 훈련한 정보나 이미 알고 있는 정보를 기반으로 응답을 생성합니다.
이에 반해 LLM + RAG는 외부 데이터를 참조할 수 있도록 가공하고, 사용자 입력에 따라 데이터베이스에서 검색합니다.
3.1. Load
데이터를 수집하고 검색하기 쉬운 형태로 가공합니다.
- LLM이 이해할 수 있는 지식 라이브러리를 생성
- 수집: Web, Directory, File, …
- 가공: Text Splitting(Chunking), Embedding, Indexing
Loading
웹, 경로, 파일 등에서 외부 데이터를 불러옵니다.
e.g. a.txt -> “세종대왕은 조선 건국 후 태어난 첫 임금으로, …”
Text Splitting(Chunking)
데이터를 의미(chunk)를 기준으로 분할하여, LLM이 잘 분석할 수 있도록 합니다.
긴 데이터를 효율적으로 처리하기 위해서는 ’의미’가 손상되지 않는 선까지 잘게 쪼개야 합니다.
만약 긴 데이터를 그대로 처리한다면, 프롬프트가 과도하게 길어지고 이는 정확도 하락과 큰 비용 소모로 이어집니다.
Embedding
문장을 벡터로 변환해 벡터 공간에 삽입하는 것으로, 검색 시간을 단축하고 정확도를 높입니다.
Embedding 자체는 LLM 본연의 기능이긴 하지만, LangChain과 같은 RAG 애플리케이션들도 데이터베이스를 편리하게 생성할 수 있도록 여러 모듈들을 지원합니다.
Embedding 과정은 비용이 부과되기에, 같은 문서를 매번 Embedding 하지 않고 결과를 메모리에 적재하는 편 입니다.
Indexing
검색이 용이하도록 색인화 & 정렬 및 분리하는 것으로, 이 작업 또한 검색 시간을 단축하고 정확도를 높입니다.
3.2. Store
외부 데이터를 벡터 데이터베이스로 저장합니다.
3.3. Retrieve
관련성 검색을 수행합니다.
- 사용자 질의 과정에서 수행
- 저장된 벡터 데이터베이스에서 검색
3.4. Generation
검색된 관련 데이터를 context에 추가하여 사용자 입력을 보강합니다.
- 사용자 질의 과정에서 수행
- 대규모 언어 모델과 검색된 결과를 연계해 하나의 결과를 생성
Context Integration
원래 입력과 문서에서 추출된 관련 정보를 결합합니다.
4. RAGs
| Name | First Release |
|---|---|
| LangChain | 2022.10 |
| llama-index | 2022.11 |
| Haystack | 2020.05 |
| Hugging Face - Transformers | 2020.05 |
| FAISS(Facebook AI Similarity Search) | 2017 |
| OpenAI Retrieval Plugin | - |
5. References
- Amazon AWS - RAG
- Google Cloud - RAG
- NVIDIA - What is Retrieval-Augmented Generation, RAG?
- modulabs - retrieval-augmented-generation
- 두꺼비는 두껍다 - 논문리뷰 LaMDA : Language Models for Dialog Applications
- 엉드루 블로그 - LLM을 쓰려면 역시 LangChain 4편 - RAG
- R, Python 분석과 프로그래밍의 친구 (by R Friend) - RAG는 무엇이고, LangChain으로 어떻게 구현하나?
- 가볍게 훑어보는 LangChain (랭체인)
- LangChain Official Docs - Text Splitters
- LangChain을 이용한 영화 추천기 개발일지 - 2

{kind=link}